Hey folks! Ever had that heart-stopping moment when you open a cloud or monitoring service bill and it’s way, way higher than expected? 😱 Yeah, that recently happened to a friend of mine. His Datadog invoice showed over 1000 “On-Demand Infrastructure Host (Pro) – Monthly” units, each costing $0.03. Individually, that $0.03 doesn’t sound like much, but multiply that by a thousand (or more!), and ouch, it adds up fast!
The culprit? Unexpectedly high “infra host hours” generated by his AWS EC2 instances running a Docker Swarm cluster. Let’s break down what went wrong and how we reined in those costs.
The Problem: Auto Scaling Gone Wild 🌪️
My friend’s setup involved Docker Swarm for container orchestration (kudos for keeping it simple with a small team!) running on AWS EC2 instances managed by an Auto Scaling group. The idea behind auto-scaling is great: automatically adjust the number of EC2 instances based on application load. Need more power? Spin up new instances. Load drops? Terminate unneeded ones.
However, his auto-scaling was a bit too enthusiastic. Due to fluctuating loads, new VMs were frequently starting and stopping. Here’s the kicker with Datadog’s billing (and many monitoring services): even if an instance is up for just 15 minutes of an hour, Datadog often counts it as a full billable host for that hour. So, if an instance starts, runs for a bit, terminates, and then another new instance spins up within that same hour to replace it, BAM! That’s two “infra host hours” counted. You can see how this quickly snowballs.
Datadog themselves explain their billing clearly, but it’s easy to overlook how your infrastructure behavior impacts it. You can check out their official documentation on Datadog Billing for the nitty-gritty.
The Fix: Enter EC2 Warm Pools with Instance Reuse 🔥➡️💧
After digging into the issue, I suggested implementing AWS EC2 Warm Pools with the instance reuse feature enabled.
What’s a Warm Pool, you ask? According to AWS Documentation on Warm Pools for Amazon EC2 Auto Scaling, it’s a pool of pre-initialized EC2 instances. When your Auto Scaling group needs to scale out, it can pull from this warm pool, making the new instances available to serve traffic much faster.
The real magic for our cost problem, though, is the “Instance reuse” setting. When an Auto Scaling group scales in (i.e., reduces capacity), instead of terminating the instances, it returns them to the warm pool in a stopped state. When it needs to scale out again, it reuses these stopped instances.
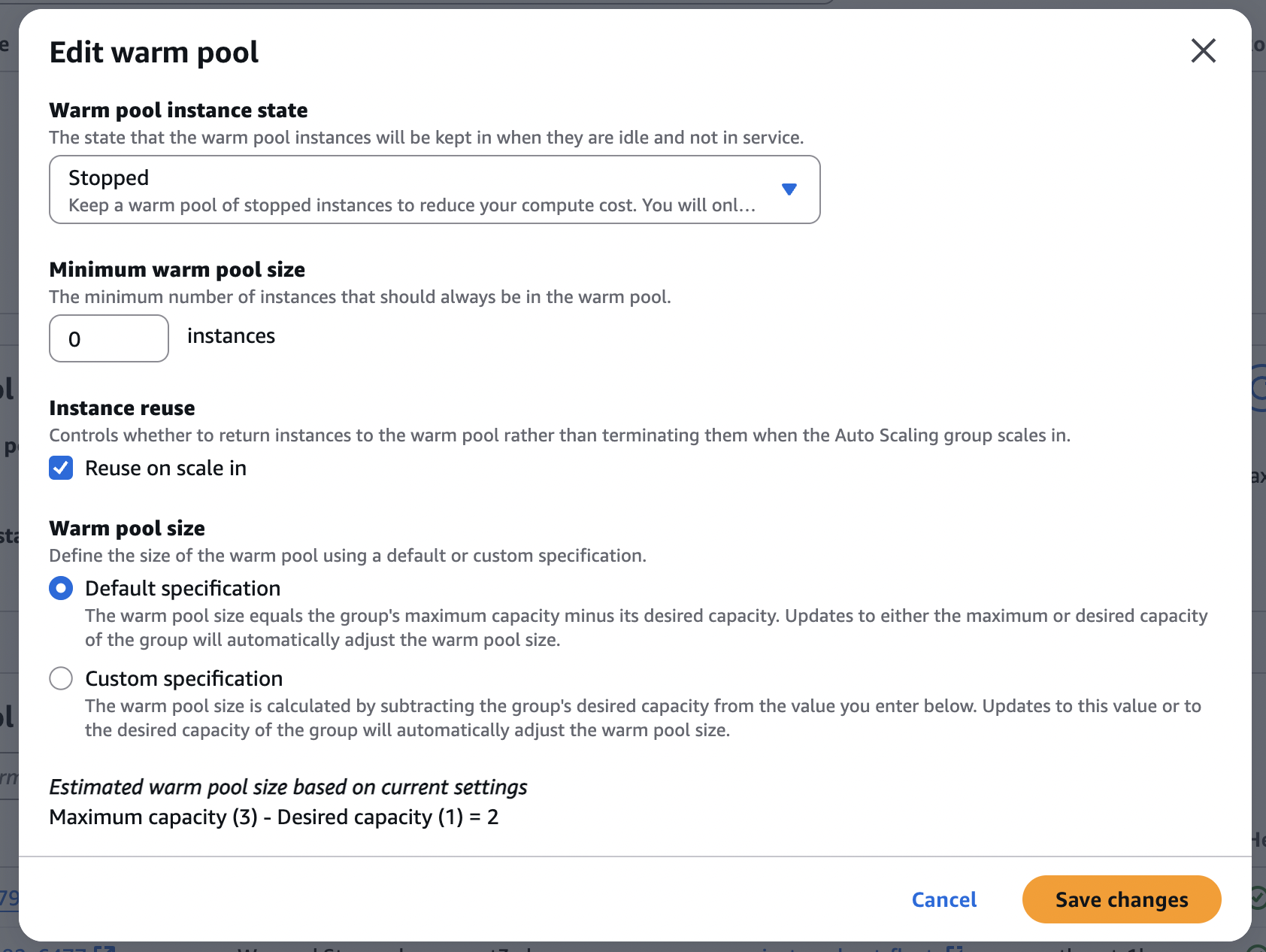
Why does this slash Datadog costs? Because you’re not constantly terminating old instances and launching brand new ones. You’re essentially recycling the same instances. Fewer unique instances showing up each hour means significantly fewer “infra host hours” billed by Datadog.
For example, if your desired capacity is 3, AWS will keep those instances around. When not needed for active load, they’ll be in a stopped state. You won’t be charged for the EC2 compute while they’re stopped (though you’ll still incur charges for associated resources like EBS volumes, as detailed by AWS EC2 Pricing). But critically, Datadog sees the same hosts stopping and starting, not an endless parade of new ones.
The “Gotcha!”: The Dreaded Mixed Instances Policy Error 🚧
My friend was sold on the idea and went to implement Warm Pools. But then, AWS threw a spanner in the works with this error:
"You cannot add a Warm Pool to an Auto Scaling group that utilizes a mixed instances policy or requests Spot Instances through its launch template or launch configuration."
Huh? He wasn’t intentionally using a mixed instances policy (which allows you to combine On-Demand and Spot Instances, or different instance types). He only had one instance type defined in his Auto Scaling group configuration. Even Amazon Q, the AI assistant, wasn’t particularly helpful in this scenario.
After a few hours of head-scratching and digging, we found the culprit: the Launch Template configuration.
Here’s the breakdown of our troubleshooting and solution:
- The Initial Setup:
- His Launch Template did not specify a particular instance type. It was left open.
- His Auto Scaling group configuration did specify a single instance type (e.g.,
m5.large).
- The Misunderstanding: We initially thought, “Hey, we’re only defining one instance type in the end, so it shouldn’t be considered ‘mixed’.” AWS, it seems, has a stricter interpretation when Warm Pools come into play.
- The Solution:
- We modified the Launch Template to explicitly specify the desired instance type (e.g.,
m5.large). - We created a new version of this updated Launch Template.
- We updated the Auto Scaling group to use this latest version of the Launch Template.
- Crucially, we removed the instance type override from the Auto Scaling group configuration itself, letting the Launch Template be the sole source of truth for the instance type.
- We modified the Launch Template to explicitly specify the desired instance type (e.g.,
Boom! Error gone. He could now enable the Warm Pool with instance reuse. More details on launch templates can be found in the AWS Launch Templates Documentation.
The Sweet Relief: Costs Under Control ✅
Now, instead of seeing hundreds of unique VMs cycling through, his Datadog dashboard reflects a number of hosts much closer to his Auto Scaling group’s desired capacity. The instances are simply stopped when demand is low and started again when needed, drastically cutting down those billable “infra host hours.”
I know some of you might be thinking, “Why not Kubernetes?” And that’s a valid question! Kubernetes is powerful. But for my friend’s small engineering team without a dedicated DevOps specialist, sticking with Docker Swarm was a pragmatic choice for its simplicity and lower operational overhead. Sometimes, the “best” solution is the one that fits your team’s current capabilities and needs.
So, if you’re seeing those Datadog “infra host hours” creep up and you’re using EC2 Auto Scaling, take a look at Warm Pools with instance reuse. And if you hit that “mixed instances policy” wall, check your Launch Template!
Hope this helps someone out there save a few bucks (or a lot more!). Let me know in the comments if you’ve faced similar issues or have other cost-saving tips for Datadog and AWS!
Leave a Reply
You must be logged in to post a comment.